What is Paywalled Content?
Paywalled content refers to articles, research papers, and other online resources that require a subscription or a one-time payment for access. News websites, academic journals, and other platforms that provide exclusive or specialized information may have paywalls. A subscription or payment is often required before users can access this content.
Why are Paywalls Used?
Publishers and content creators use paywalls for a variety of reasons:
To sustain their operations, pay their staff, and invest in the production of high-quality content, many websites and publications rely on subscription revenues.
Paywalls allow publishers to create a sense of exclusivity by offering subscribers premium content not available elsewhere for free.
A paywall allows publishers to maintain control over their intellectual property, preventing unauthorized use or distribution.
The Frustrations of Paywalled Content
The use of paywalls can be frustrating for readers despite their intended purpose:
Paywalls can limit access to information, making it difficult for those without means to gain access to important research or news.
Readers may find themselves juggling multiple subscriptions as more websites adopt paywalls, which can be expensive and time-consuming.
The inconvenience of paywalls is that they can interrupt the seamless browsing experience that users have come to expect, causing them to seek alternative means of accessing the content they seek.
How to legally bypass a paywall
For this example, I will use a paywalled article on The Globe and Mail
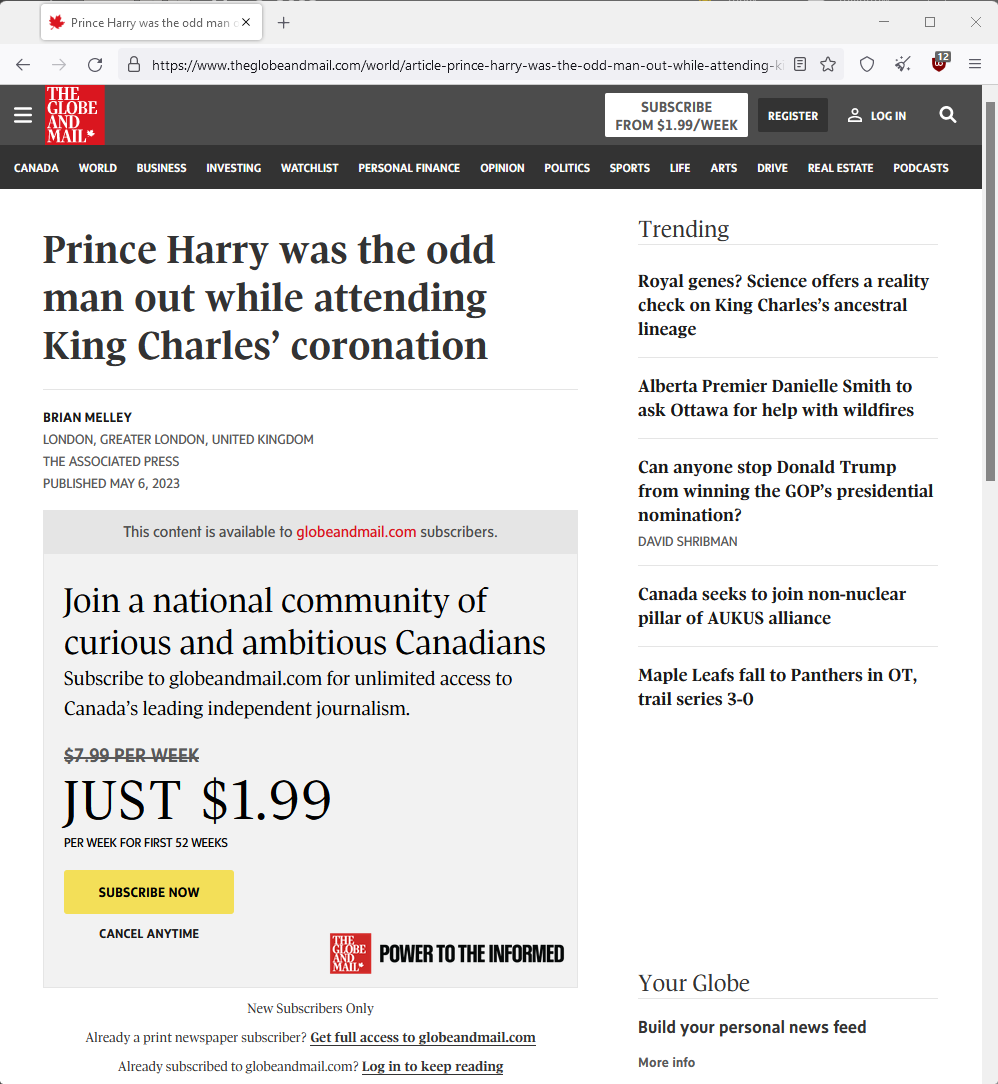
All you have to do it add archive.is/ between the https// and the www.

You will then be presented with the archive of the different versions archive.is has stored. NOrmally I recommend picking the last version available.
Now you will be able to read the article from archive.is for free

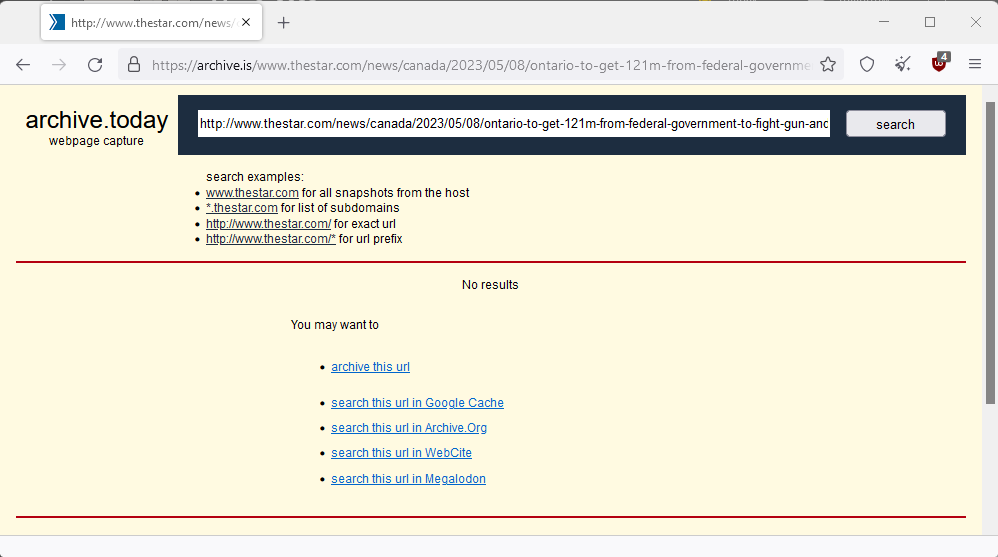
When the content isn’t already cached
Archive.is does a fantastic job of archiving most of the content you will want to read, but once in a while, you may stumble on something that isn’t archived yet. you will then see this screen. Click on “archive this url”
Then click on the Save button

You will get a Loading page that may take 5-10 minutes to complete

And voila, the site is cached and fully displayed for your reading pleasure.

What is archive.is?
Archive.is (formerly Archive.today) allows users to save snapshots of web pages for future reference. Using the platform, you can preserve the content of web pages even if the original source is removed or modified, ensuring that valuable information remains available.
Archive.is was founded by an anonymous individual who prefers to remain anonymous. They created the platform to provide users with a free and easy-to-access tool for preserving web content for various purposes, including research, legal evidence, and personal records.
Archive.is serves several key purposes:
This service allows users to save snapshots of web pages, ensuring that important information is preserved even if the original source is removed, edited, or otherwise altered.
In some instances, Archive.is provides snapshots of websites that would otherwise be restricted, allowing users to bypass paywalls.
The platform provides a valuable resource for researchers, journalists, and other users who require access to historical web content.
Keywords: #ArchiveIs #BypassPaywalls #LegalAccess #FreeContent #WebPreservation #OnlineResearch #PaywallHacks #UnlockKnowledge #DigitalArchiving #OpenAccess #ContentFreedom #NoMorePaywalls #PaywallSolutions #KnowledgeForAll

